
It's been a while since my last post, but I've been working on a pretty big project. Please note that this post is going to be different from usual. I won't be containing any specific code for this completed project since that would make this post far longer than I intend. Instead, I will simply be discussing the theory behind my project and the results I acquired. Since I'm mostly switching the focus of my projects from computer science to physics, expect most of my future posts to follow this format - more theory and less code.
As long-range autonomous space exploration becomes more prevalent, the need for efficient and reliable autonomous exoplanetary landing systems, especially for previously unmapped terrain, is becoming increasingly crucial. To address this need, I proposed a novel approach to training autonomous space vehicles to land on variable terrain using value-based reinforcement learning techniques. In my experiment, I generated terrain procedurally from a noise function and demonstrated the effectiveness of the proposed approach in allowing autonomous spacecraft to land in remote locations.
Compared to existing self-landing autonomous space vehicles, which primarily rely on pre-programmed trajectory planning, the proposed approach enables greater flexibility and adaptability in responding to unforeseen situations.
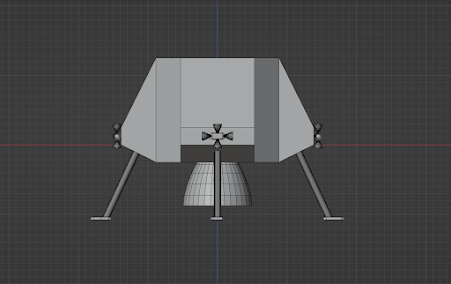
The simulated lander is a robust single-stage spacecraft, specifically designed for autonomous exoplanetary landing. It has one main engine and 16 RCS thrusters mounted in 4 clusters. If you haven't noticed yet, it's meant to strongly resemble the LEM from the Apollo missions, but smaller and lighter. The actual specific design of the lander shouldn't matter too much, though, since this general theory is meant to be applicable to lots of different spacecrafts.
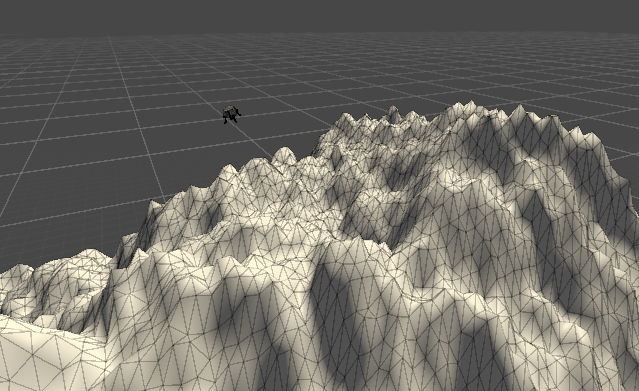


Unity, the Unity MLAgents package and PyTorch were used to train the lander. For procedural terrain, I used generative meshes and an iterative, octave-based Perlin noise algorithm, with a total simulated terrain size of 2500 square meters (see my previous post on procedural terrain.) A new terrain mesh was generated each episode using a randomized seed. The agent was trained in a -1.62m/s^2 gravitational field, simulating lunar gravity.
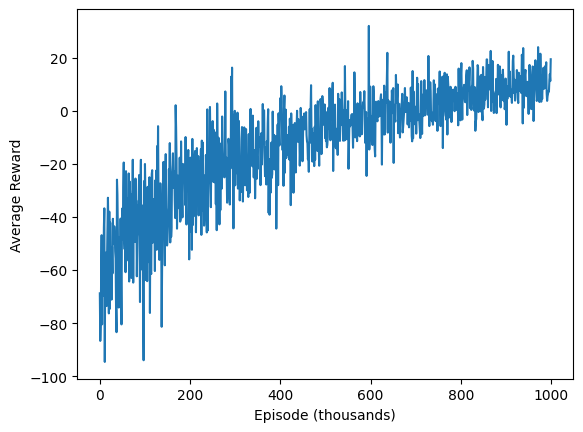
Comments
Post a Comment